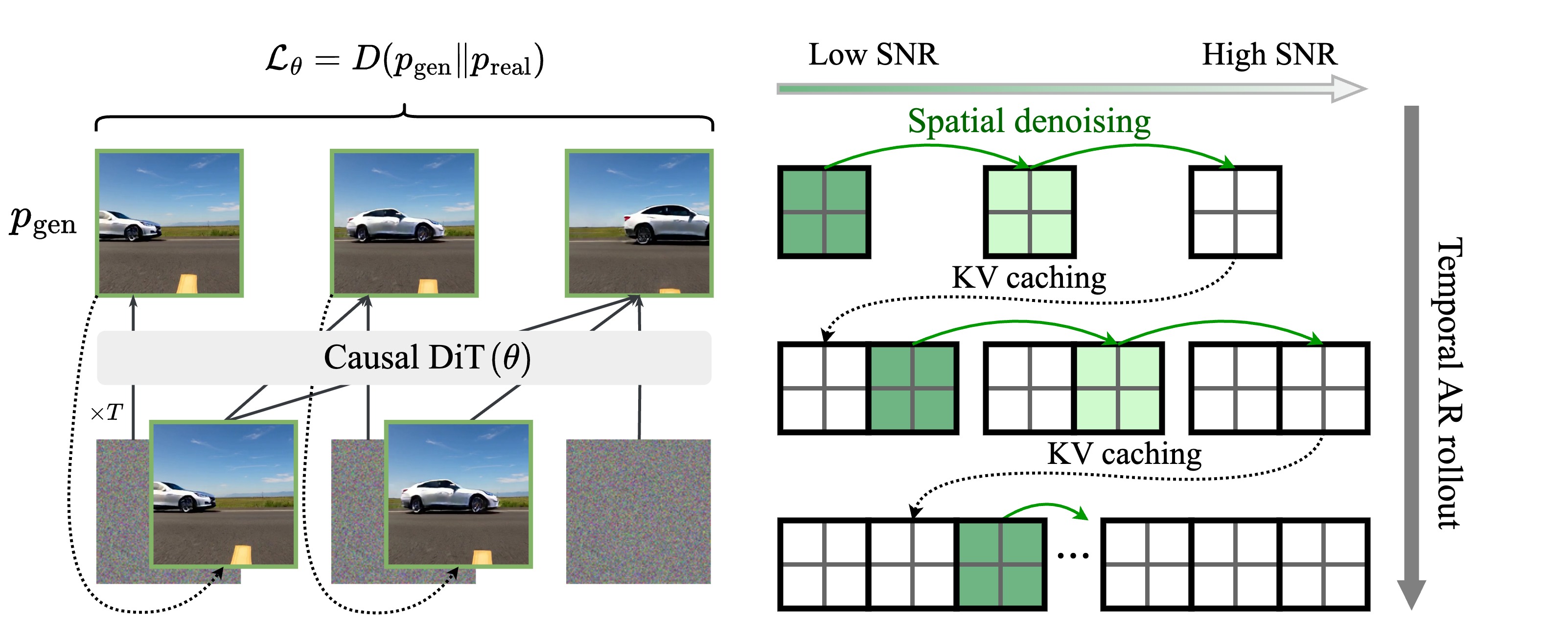
Self Forcing trains autoregressive video diffusion models by simulating the inference process during training, performing autoregressive rollout with KV caching. It resolves the train-test distribution mismatch and enables real-time, streaming video generation on a single RTX 4090 while matching the quality of state-of-the-art diffusion models.
Our model generates high-quality 480P videos with an initial latency of ~0.8 seconds, after which
frames are generated in a streaming fashion at ~16 FPS on a single H100 GPU and ~10 FPS on a single 4090 with some optimizations.
Below, we show 5-second videos (top) and extrapolated 10-second videos (bottom) generated by our model. [More Examples]
A close-up shot of a ceramic teacup slowly pouring water into a glass mug. The water flows smoothly from the spout of the teacup into the mug, creating gentle ripples as it fills up. Both cups have detailed textures, with the teacup having a matte finish and the glass mug showcasing clear transparency. The background is a blurred kitchen countertop, adding context without distracting from the central action. The pouring motion is fluid and natural, emphasizing the interaction between the two cups.
A dynamic and chaotic scene in a dense forest during a heavy rainstorm, capturing a real girl frantically running through the foliage. Her wild hair flows behind her as she sprints, her arms flailing and her face contorted in fear and desperation. Behind her, various animals—rabbits, deer, and birds—are also running, creating a frenzied atmosphere. The girl's clothes are soaked, clinging to her body, and she is screaming and shouting as she tries to escape. The background is a blur of greenery and rain-drenched trees, with occasional glimpses of the darkening sky. A wide-angle shot from a low angle, emphasizing the urgency and chaos of the moment.
A dynamic over-the-shoulder perspective of a chef meticulously plating a dish in a bustling kitchen. The chef, a middle-aged man with a neatly trimmed beard and focused expression, deftly arranges ingredients on a pristine white plate. His hands move with precision, each gesture deliberate and practiced. The background shows a crowded kitchen with steaming pots, whirring blenders, and the clatter of utensils. Bright lights highlight the scene, casting shadows across the busy workspace. The camera angle captures the chef's detailed work from behind, emphasizing his skill and dedication.
A single white sheep bending down to drink water from a calm river. The sheep has fluffy wool, long curved horns, and soft brown eyes. It is positioned near the riverbank, with its front legs partially submerged in the clear water. The river flows gently, reflecting the surrounding greenery and blue sky. The background shows lush grass and trees along the riverbank, creating a serene pastoral landscape. The sheep's body is slightly tilted as it bends down to drink, emphasizing a natural and tranquil motion. Medium close-up shot focusing on the sheep and the river.
A playful raccoon is seen playing an electronic guitar, strumming the strings with its front paws. The raccoon has distinctive black facial markings and a bushy tail. It sits comfortably on a small stool, its body slightly tilted as it focuses intently on the instrument. The setting is a cozy, dimly lit room with vintage posters on the walls, adding a retro vibe. The raccoon's expressive eyes convey a sense of joy and concentration. Medium close-up shot, focusing on the raccoon's face and hands interacting with the guitar.
A dramatic and dynamic scene in the style of a disaster movie, depicting a powerful tsunami rushing through a narrow alley in Bulgaria. The water is turbulent and chaotic, with waves crashing violently against the walls and buildings on either side. The alley is lined with old, weathered houses, their facades partially submerged and splintered. The camera angle is low, capturing the full force of the tsunami as it surges forward, creating a sense of urgency and danger. People can be seen running frantically, adding to the chaos. The background features a distant horizon, hinting at the larger scale of the tsunami. A dynamic, sweeping shot from a low-angle perspective, emphasizing the movement and intensity of the event.
While Self Forcing relies on sequential rollout, it is surprisingly efficient and obtains better quality with the same training budget. This is mainly because we still maintain sufficient parallelism even processing one frame at a time.

Our method has the same speed as CausVid but has much better video quality, free from over-saturation artifacts and having more natural motion. Compared to Wan, SkyReels, and MAGI, our approach is 150–400× faster in terms of latency, while achieving comparable or superior visual quality.
Wan2.1-1.3B
SkyReels2-1.3B
MAGI-1-4.5B
CausVid-1.3B
Ours-1.3B
A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about.
A petri dish with a bamboo forest growing within it that has tiny red pandas running around.
An adorable happy otter confidently stands on a surfboard wearing a yellow lifejacket, riding along turquoise tropical waters near lush tropical islands, 3D digital render art style.
Chunk-wise, SiD
Chunk-wise, GAN
Chunk-wise, DMD
Animated scene features a close-up of a short fluffy monster kneeling beside a melting red candle.
Frame-wise, SiD
Frame-wise, GAN
Frame-wise, DMD
A close up view of a glass sphere that has a zen garden within it. There is a small dwarf in the sphere who is raking the zen garden and creating patterns in the sand.
While Self Forcing addresses exposure bias and we observe no error accumulation within the video length the model is trained on (5 seocnds), we still observe quality degradation when extrapolating beyond its training horizon. Below we show 30-second videos generated via sliding window extrapolation.
This close-up shot of a Victoria crowned pigeon showcases its striking blue plumage and red chest...
A cartoon kangaroo disco dances.
A Chinese Lunar New Year celebration video with Chinese Dragon.
3D animation of a small, round, fluffy creature with big, expressive eyes explores a vibrant, enchanted forest...
@article{huang2025selfforcing,
title={Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion},
author={Huang, Xun and Li, Zhengqi and He, Guande and Zhou, Mingyuan and Shechtman, Eli},
journal={arXiv preprint arXiv:2506.08009},
year={2025}
}